
Knowledge graph overview
Understand how ctx| turns repositories into an organization-scoped graph of systems, claims, and relationships.
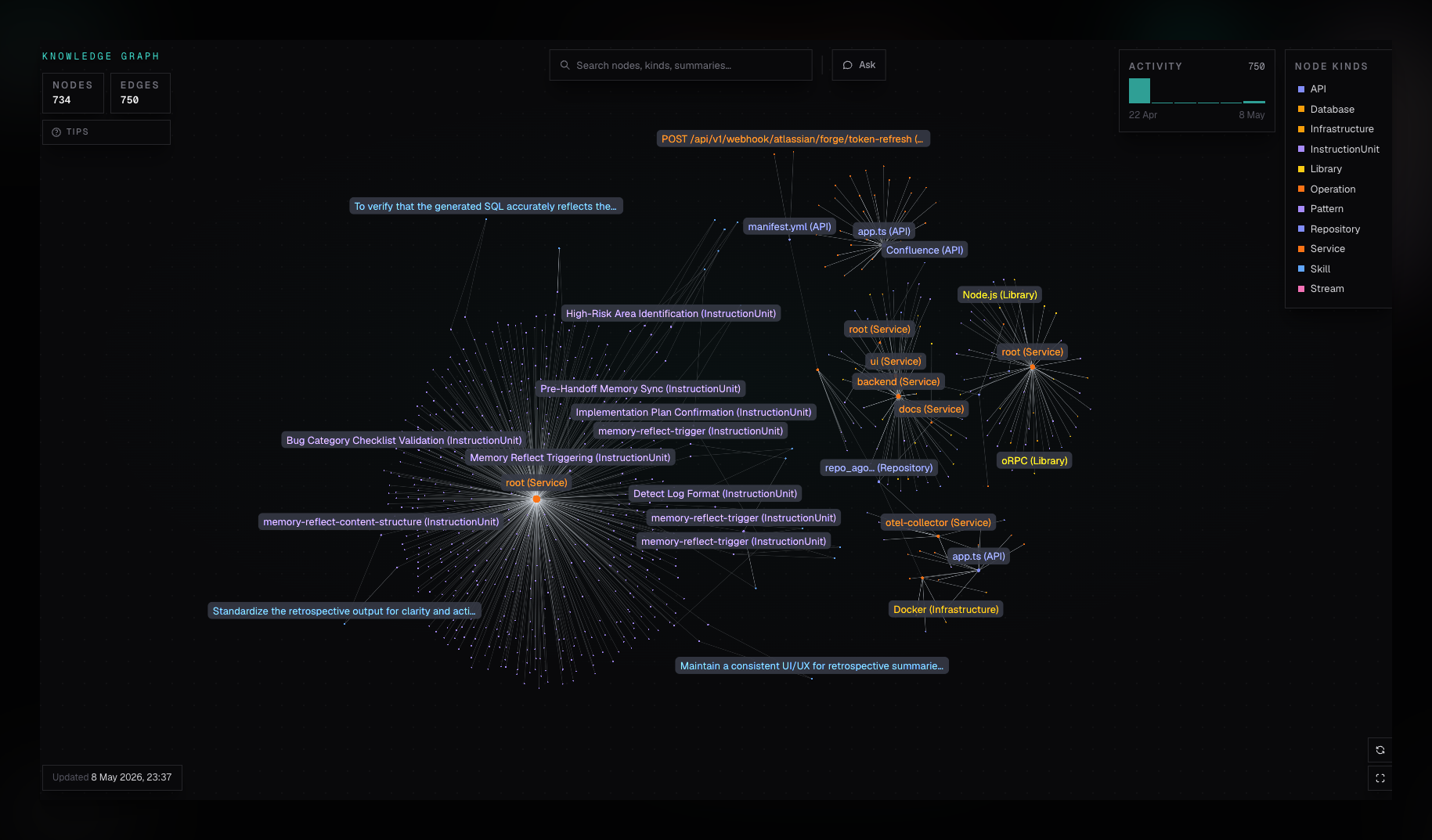
The knowledge graph is ctx|'s structured model of an organization. It turns indexed repositories and repo-native documentation into nodes and relationships that Chat and MCP can use for technical reasoning.
What the Graph Represents
The graph is built from extracted claims. A claim connects a subject to an object with a predicate, timestamp, and confidence.
Typical node kinds include:
Service,App,Library,APIDatabase,Stream,InfrastructurePattern,InstructionUnit,Skill
Edges represent relationships such as calls, depends on, owns, documents, uses, or implements. The exact predicate vocabulary evolves with extraction.
Where It Comes From
The graph is populated during repository ingestion:
- A repository is registered under an organization.
- Codesearch clones and indexes the source tree.
- LangGraph ingestion extracts entities and claims.
- The graph database stores those claims in an org-isolated graph.
- The UI reads a graph snapshot for exploration.
See Ingestion explanation for the full pipeline.
How It Is Used
The graph powers three product surfaces:
- Knowledge graph UI: visual exploration under
/:orgSlug/knowledge-graph. - Chat: natural-language questions over graph context and source code.
- MCP:
ctx_advisoruses graph and repository context for agent workflows.
API Shape
The browser reads:
GET /:orgSlug/api/v1/knowledge-graphOptional query parameters:
| Parameter | Meaning |
|---|---|
nodeLimit | Maximum nodes returned. |
edgeLimit | Maximum edges returned. |
The response includes metrics, nodes, and edges. Large graphs may be
truncated; when that happens the response reports both returned counts and
org-wide totals.